Joint outputs
Generated text
“A group of people with bicycles in the grass.”
Generated audio

Generated image

MUNI jointly learns modality-specific encoders, expressive decoders, and a single shared flow-based prior so one model can generate any missing modality from any observed subset, including the fully unconditional case.
“A group of people with bicycles in the grass.”
“The beach is empty and clear with palm trees.”


“A man with an acoustic guitar and shirt.”

“The room has blue curtains and red furniture.”


Unconditional image-text-audio co-generation: each triplet is sampled jointly from MUNI’s learned prior.
We introduce MUNI, an end-to-end multimodal latent diffusion framework for any-to-any generation that unifies subset-conditioned cross-modal generation and unconditional joint sampling through a shared stochastic latent. Existing multimodal generative models are largely LLM-based, which limits leveraging modality-specific generators and requires text-paired data for training. Recent diffusion- and flow-based any-to-any extensions take a different direction but still rely on text-aligned embeddings, fully-paired training, or matched-dimensionality deterministic mappings. MUNI rests on two complementary contributions, one architectural and one in the training objective. First, we extend latent diffusion to multimodal any-to-any generation end-to-end: instead of the standard two-stage recipe that precomputes a frozen latent space and then fits a prior over it, MUNI jointly trains modality-specific encoders, expressive decoders, and a single shared flow-based prior under one objective. Second, we identify that the standard aggregation rules of multimodal variational inference are insufficient once coupled with a learned prior and expressive decoders. A suitable shared latent must simultaneously satisfy coherence across generated modalities, predictive sufficiency of subset latents, and minimality of the latent content. We propose a routed training objective whose structural choices align the latent with these criteria and admit a minimal-sufficiency characterization in the realizable setting. Experiments on PolyMNIST-Quadrant-Labels and a large-scale image-text-audio benchmark show MUNI matching or exceeding the strongest baselines on conditional generation while opening its largest margins on unconditional coherence.
MUNI treats any-to-any generation as a latent-content problem. The shared latent should contain enough information to make independently decoded modalities agree, but not modality-private detail that a stochastic decoder can model.
| Criterion | What the latent should do |
|---|---|
| Coherence | A prior sample should support a coherent joint image-text-audio tuple. |
| Predictivity | A subset posterior should retain the information needed to generate every missing modality. |
| Minimality | Private variation should stay out of the shared latent and remain stochastic in each decoder. |

MUNI uses the same model for every conditioning subset. The routing choices are simple:
| Route | Purpose |
|---|---|
| Non-mixture aggregation | Fuse all observed modalities into one subset posterior. |
| Target-detached self-reconstruction | Train decoders without rewarding encoders for copying private detail. |
| Leave-one-out prior routing | Train the prior only on broad subset latents that can support coherent joint sampling. |
MUNI and MUNI† achieve the best generalist result on every many-to-one metric.
| Generalist | (I+A)→T CLIP ↑ | (I+A)→T CLAP ↑ | (T+A)→I CLIP ↑ | (T+A)→I AIS ↑ | (T+I)→A CLAP ↑ | (T+I)→A AIS ↑ |
|---|---|---|---|---|---|---|
| CoDi | 24.05 | 33.72 | 24.98 | 85.52 | 11.06 | 65.31 |
| OmniFlow | 24.73 | 36.26 | 26.41 | 81.51 | 13.50 | 63.55 |
| FlowBind | 27.54 | 39.56 | 25.23 | 86.44 | 26.83 | 80.15 |
| MUNI | 25.20 | 39.75 | 25.44 | 93.42 | 26.88 | 87.29 |
| MUNI† | 27.60 | 36.61 | 26.43 | 90.94 | 30.16 | 86.89 |
Only OmniFlow among the compared frontier generalists supports fully unconditional joint sampling. MUNI opens its largest margin in this setting.
| Method | T-I CLIP ↑ | T-A CLAP ↑ | A-I AIS ↑ |
|---|---|---|---|
| OmniFlow | 21.17 | 14.23 | 50.95 |
| MUNI | 26.76 | 23.73 | 81.24 |
| MUNI† | 26.74 | 24.83 | 82.80 |
Samples are grouped by the observed source modalities and generated target modality.
“Drums and horses playing.”

“A car is driving by and it speeds by.”

CoDi and FlowBind are omitted because this comparison is fully unconditional.
“The destroyed children are in the heart of a skull.”

“Two people standing on top of a mountain.”

CoDi and FlowBind are omitted because this comparison is fully unconditional.
“A man preparing food in the kitchen of his home.”


“A man singing and playing the guitar.”

“A table with chairs and flowers on it.”

“A man in a hat and coat walking down the street.”

“A person on top of a mountain with skis.”

“A bird perched on top of a tree branch.”


“Modern bedroom with large desk in front of window.”




“A wooden table surrounded by chairs next to a TV.”




“A dog is patiently waiting in the back of a truck.”




“A bathroom sink with a bottle of hand soap.”




“A red park bench sitting in the middle of a flooded area.”




“A vase with flowers next to a clock.”
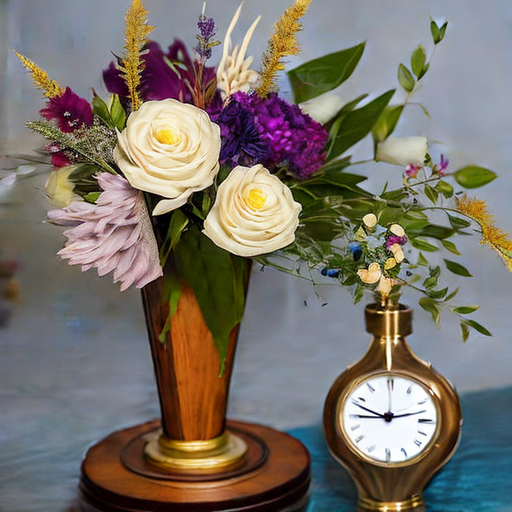




“A young boy in a baseball uniform is excited after catching a ball.”
“Mike mitt kicks his playoff pitch during the final baseball game of the year.”
“A young boy throwing a baseball with a baseball bat.”
“A boy in a white baseball uniform, shirt and visor is holding a baseball bat.”

“A cup and donut on a table with books.”
“Dog and a bag lunch on coffee.”
“A paper bag with a sandwich and a knife sitting on a wooden table.”
“A helmet with books on it sitting on a table with a dog and coffee.”

“A skillet with bananas and syrup being cooked.”
“Apple with peanuts.”
“A pan filled with fried rice and shrimp.”
“A pan with some banana flour on it.”

“A man in a tractor with cows on the road.”
“On a hill with horses and bicyclists on a truck four people don't stop.”
“A herd of cows walking down a road in a forest, with a truck parked nearby.”
“A man riding a bucking cow is driving down a road past a herd of cows.”

“A skier in purple is sliding down the slope.”
“All women finals at the 2012 olympic skiing, multiple women in the 100 olympic.”
“A person is skiing through a snowy landscape with footprints.”
“A man skis down a snowy hill as he is sliding off of a race track.”

“Two little girls are making pizzas in the kitchen.”
“Two guys making some pizza on the pizza.”
“Two children are sitting at a table with dishes.”
“A little girl is cooking pizza with a plate, while a toddler is making it.”
“A woman is talking to a baby while he cries.”
“A baby is crying and mother is born.”
“A woman and baby talking.”
“A infant crying and a woman speaking.”
“Two people talking and typing on a computer keyboard.”
“People typing.”
“A man speaks and types on a keyboard.”
“A woman speaks and then a person talks keyboard.”
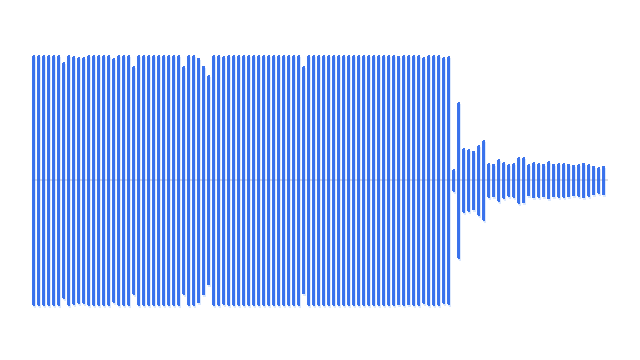
“A motorboat engine running and revving.”
“One dog coming to turn for a speeding car are speeding away.”
“Wind blows and an engine hums.”
“A boat motor is cruising then slows somewhat loudly.”
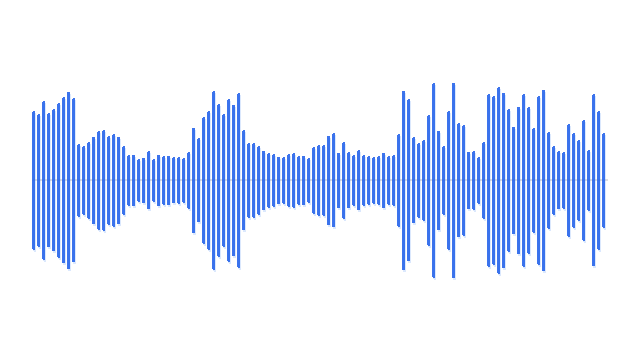
“A cat is howling and the wind is blowing.”
“Cat starts a cat < baby.”
“A cat meows and whines.”
“Loud meowing of cat, then meowing.”

“A man is speaking to an audience while others clap.”
“The man laughs to congratulate the man who says that the election is about to yell.”
“Man speaking into a microphone.”
“A man speaks with people talking then he applauds.”
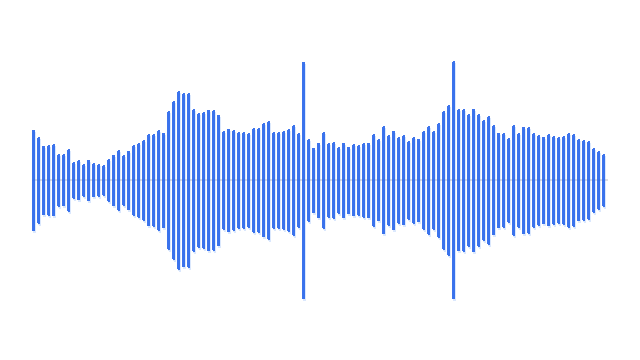
“Fireworks burst in the sky and then a burst.”
“Jump happening in a fire over a falling lake and blue rainbow.”
“Rain falls and a pop occurs.”
“Multiple popping and eruption.”
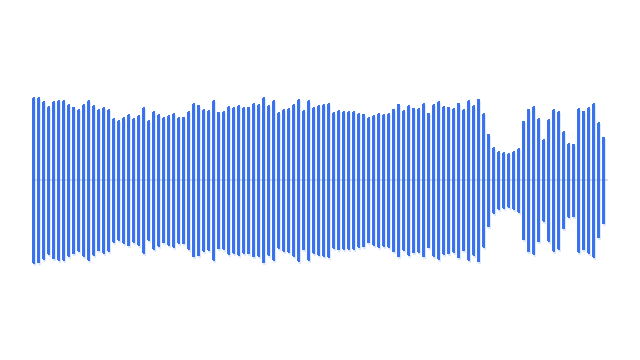


























“A man walking next to a small car.”
“A man stops for a train about to go on a car being driven by a man.”
“A man sits in a truck, working on an engine.”
“The vehicle motor is driving down the road.”

“A man playing an acoustic guitar and another person sitting on the bench.”
“A man is speaking to a person in the city talking while walking for the man.”
“A man talking with a crowd talking in the background.”
“A man sitting at a park bench while music is playing.”

“A helicopter is flying through the air.”
“Airplane.”
“A helicopter hovering in the distance, with.”
“A helicopter flying over with muffled helicopter.”

“A man in sunglasses is driving on the water.”
“Man driving in a blue car race to turn mid-way on his car engine, is speeding.”
“A man is working on a boat in the water.”
“A man motor is on a boat in the water boating.”

“A man is talking to some people and there is a dog.”
“A man is jaying after a dog says to his dog greeting. as he walks on the dog.”
“A man talking in a movie, with a blurry background.”
“A man speaking with someone.”

“A police car is going by with sirens.”
“Red traffic car for a road red.”
“A darkened city street with a siren blaring in the distance,.”
“A police siren is signaling while sirens are.”
“A vehicle is running on the mountain.”




“A woman is speaking in the hospital.”



“There is a man in front of the building.”




“A man is standing outside.”




“It's a sunny day.”




“A man is on the outside.”




“pigeons coo and flap their wings”

“a telephone ringing”

“water makes gurgling sound”

“a person speaking and various laughter and clapping”
“A clock ticks repeatedly”

“a male speaking over a microphone”

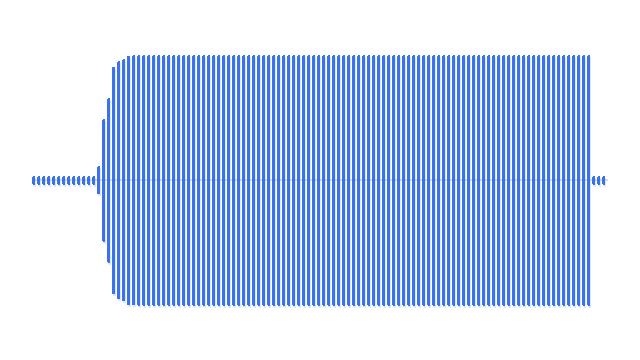

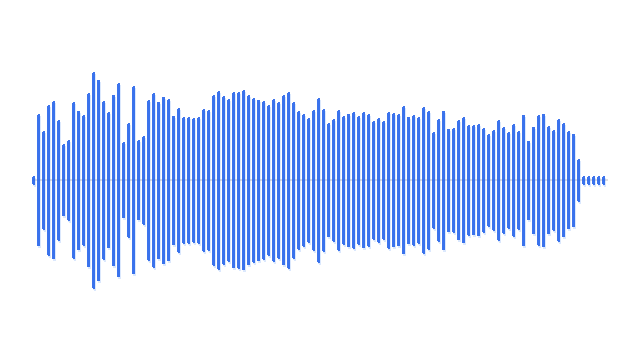
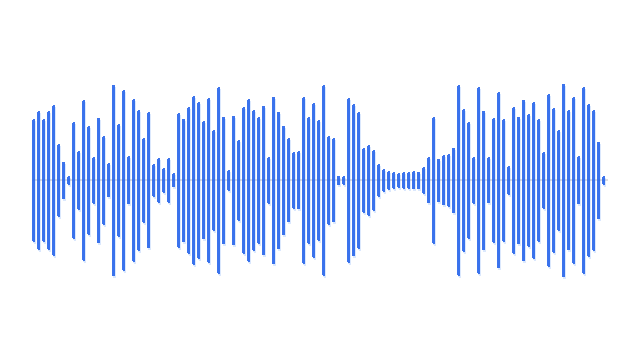
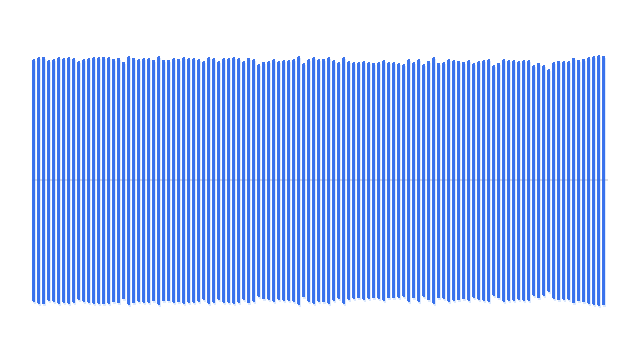


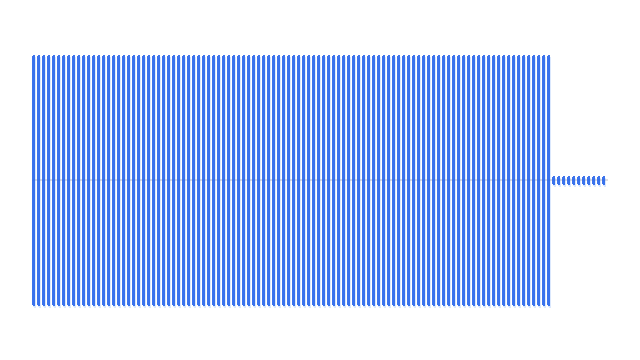

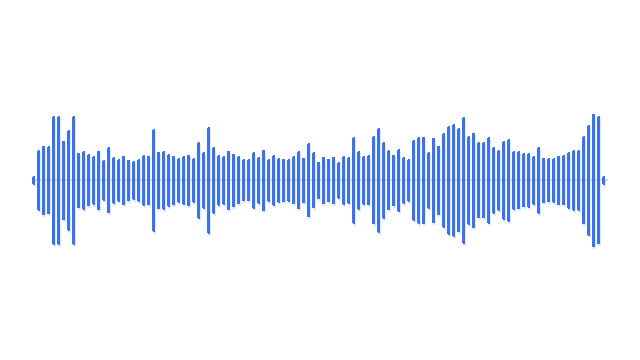
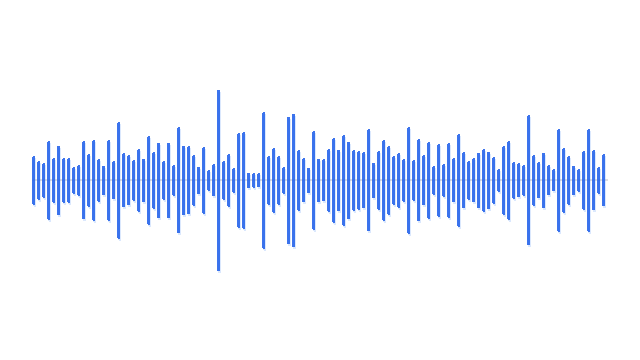
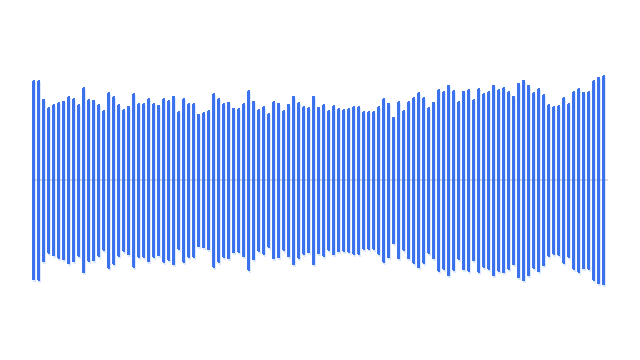

“A man playing acoustic guitar on a wooden stage.”

“It's a rainy day.”


“Someone is typing.”


“A crowd is cheering.”

“A machine is running.”

“An engine is running.”


PolyMNIST-Quadrant-Labels is a controlled setting for checking whether jointly sampled modalities agree on digit identity and quadrant position. It is useful diagnostically, but the main webpage emphasis is the image-text-audio result above.
| Method | Single-L→I Digit ↑ | Single-L→I Quadrant ↑ | Multi-L→I Both ↑ | Uncond. Coherence ↑ |
|---|---|---|---|---|
| MVAE | 0.4137 | 0.6803 | 0.7053 | 0.0079 |
| MMVAE | 0.9279 | 0.9999 | 0.1630 | 0.3167 |
| MoPoE | 0.9199 | 0.9999 | 0.9283 | 0.3943 |
| HELVAE | 0.9297 | 0.9999 | 0.7654 | 0.4246 |
| MUNI | 0.9131 | 0.9999 | 0.9346 | 0.4841 |
| MVAE | MMVAE | MoPoE | HELVAE | MUNI |
|---|---|---|---|---|
 |  |  |  |  |
@misc{yeo2026muni, title = {MUNI: Multimodal Unified Latent Diffusion for Coherent Any-to-Any Generation}, author = {Yeo, Kyeongmin and Min, Yunhong and Sung, Minhyuk}, year = {2026}, eprint = {TBA}, archivePrefix = {arXiv}, primaryClass = {cs.CV}, url = {TBA}}